JavaScript中的正则表达式
正则表达式图形化工具Regexper
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
元字符
正则表达式由两种基本字符类型组成:
原义文本字符
元字符
元字符是在正则表达式中有特殊含义的非字母字符
* + ? $ ^ . | \ ( ) { } [ ]
字符类
- 一般情况下正则表达式一个字符对应字符串一个字符
- 我们可以使用元字符
[]来构建一个简单的类 - 所谓类是指符合某些特征的对象,一个泛指,而不是特指某个字符
- 表达式
[abc]把字符a或b或c归为一类,表达式可以匹配这类的字符
字符类取反
- 使用元字符
^创建反向类/负向类 - 反向类的意思是不属于某类的内容
- 表达式
[^abc]表示不是字符a或b或c的内容
范围类
- 正则表达式还提供了范围类
- 所以我们可以使用
[a-z]来连接两个字符表示从a到z的任意字符 - 这是个闭区间,也就是包含
a和z本身 - 在
[]组成的类内部是可以连写的[a-zA-Z]
比如:
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','js2015'等等[a-zA-Z\_\$][0-9a-zA-Z\_\$]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)
预定义类
| 字符 | 等价类 | 含义 |
|---|---|---|
. |
[^\r\n] |
除了回车符和换行符之外的所有字符 |
\d |
[0-9] |
数字字符 |
\D |
[^0-9] |
非数字字符 |
\s |
[\t\n\x0B\f\r] |
空白符 |
\S |
[^\t\n\x0B\f\r] |
非空白符 |
\w |
[a-zA-Z_0-9] |
单词字符(字母、数字、下划线) |
\W |
[^a-zA-Z_0-9] |
非单词字符 |
边界
| 字符 | 含义 |
|---|---|
^ |
以xxx开始 |
$ |
以xxx结束 |
\b |
单词边界 |
\B |
非单词边界 |
量词
| 字符 | 含义 |
|---|---|
? |
出现零次或一次(最多出现一次) |
+ |
出现一次或多次(至少出现一次) |
* |
出现零次或多次(任意次) |
{n} |
出现n次 |
{n,m} |
出现n到m次 |
{n,} |
至少出现n次 |
在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,\w可以匹配一个字母或数字,所以:
'00\d'可以匹配'007',但无法匹配'00A';
'\d\d\d'可以匹配'010';
'\w\w'可以匹配'js';
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符(也就是上面所说的量词)
分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(group)。比如:
^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
如果正则表达式中定义了组,就可以在RegExp对象上用exec()方法提取出子串来。
exec()方法在匹配成功后,会返回一个Array,第一个元素是正则表达式匹配到的整个字符串,后面的字符串表示匹配成功的子串。
exec()方法在匹配失败时返回null。
使量词作用于分组:
或
|,正则表达式中的或,把|左右两边的一到多个字符当成一个整体对待
b|c表示,匹配b或者c(这里相当于[bc])。ab|ac表示匹配ab或ac(但这里不相当于[abc],[]表示在一组字符中任选一个)
反向引用
2014-12-25 => 12/25/2014
|
|
忽略分组
不希望捕获某些分组,只需要在分组内加上? :就可以
比如:

创建一个正则表达式
JavaScript有两种方式创建一个正则表达式:
第一种方式是直接通过/正则表达式/写出来,第二种方式是通过new RegExp('正则表达式')创建一个RegExp对象。
两种写法是一样的:
注意,如果使用第二种写法,因为字符串的转义问题,字符串的两个\\实际上是一个\。
先看看如何判断正则表达式是否匹配:
RegExp对象的test()方法用于测试给定的字符串是否符合条件。
切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
嗯,无法识别连续的空格,用正则表达式试试:
无论多少个空格都可以正常分割。加入,试试:
再加入;试试:
如果用户输入了一组标签,下次记得用正则表达式来把不规范的输入转化成正确的数组。
贪婪匹配
需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:

由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:

Chrome浏览器控制台输出结果: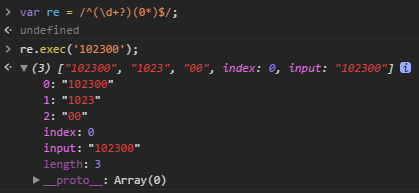
全局搜索
JavaScript的正则表达式还有几个特殊的标志,最常用的是g,表示全局匹配:
全局匹配可以多次执行exec()方法来搜索一个匹配的字符串。当我们指定g标志后,每次运行exec(),正则表达式本身会更新lastIndex属性,表示上次匹配到的最后索引:
全局匹配类似搜索,因此不能使用/^...$/,那样只会最多匹配一次。
正则表达式还可以指定i标志,表示忽略大小写,m标志,表示执行多行匹配。
一个匹配邮箱的正则表达式
下图是用正则表达式图形化工具Regexper生成的对应图片
